Overview
mineru-runpod is a generic, reusable MinerU PDF-parsing service running on RunPod Serverless. MinerU 3.2.x runtime with the MinerU2.5-Pro-2605-1.2B VLM by default. The repo deliberately knows nothing about any specific downstream system — it ships a worker image, a small Python client, and the deploy / destroy glue. Anything that needs PDF → structured Markdown + JSON (a RAG pipeline, a document indexer, an Office-doc archive) calls it the same way.
What’s in the repo
Section titled “What’s in the repo”handler.py— the serverless worker. Accepts a PDF via URL, base64, or mounted-volume path; calls MinerU’s async parse; returns Markdown +content_list+middle.json+ images.mineru_client/— the Python package consumers import. One class (MineruClient), two methods (parse_document,parse_document_from_file). Pure-Python; imports nothing GPU- or MinerU-related, so it’s safe to depend on from any caller.deploy.py/destroy.py— stand up and tear down the RunPod endpoint from CLI flags. Every dashboard setting is exposed as a flag..runpod/hub.json— disabled RunPod Hub listing metadata (title, description, GPU pool list, CUDA versions).examples/—parse_url_example.py,parse_b64_example.py, and aparser_adapter_example.pyshowing how to wrap MinerU output in your own typed domain model.
Who it’s for
Section titled “Who it’s for”| If you’re building… | What you get |
|---|---|
| Office document indexing (Word / PowerPoint / Excel exported to PDF) | Spiky ingest, pay only during bursts; preserves tables + figures |
| Document RAG pipelines | Section-aware chunks with page provenance out of the box |
| Contract / spec / standards parsing | Handles long attribute tables and cross-page constructs |
| Invoice / receipt extraction | Table fidelity + image extraction in one pass |
| Multi-language documents | MinerU’s pipeline backend supports 109 languages, including handwriting |
Why MinerU + serverless
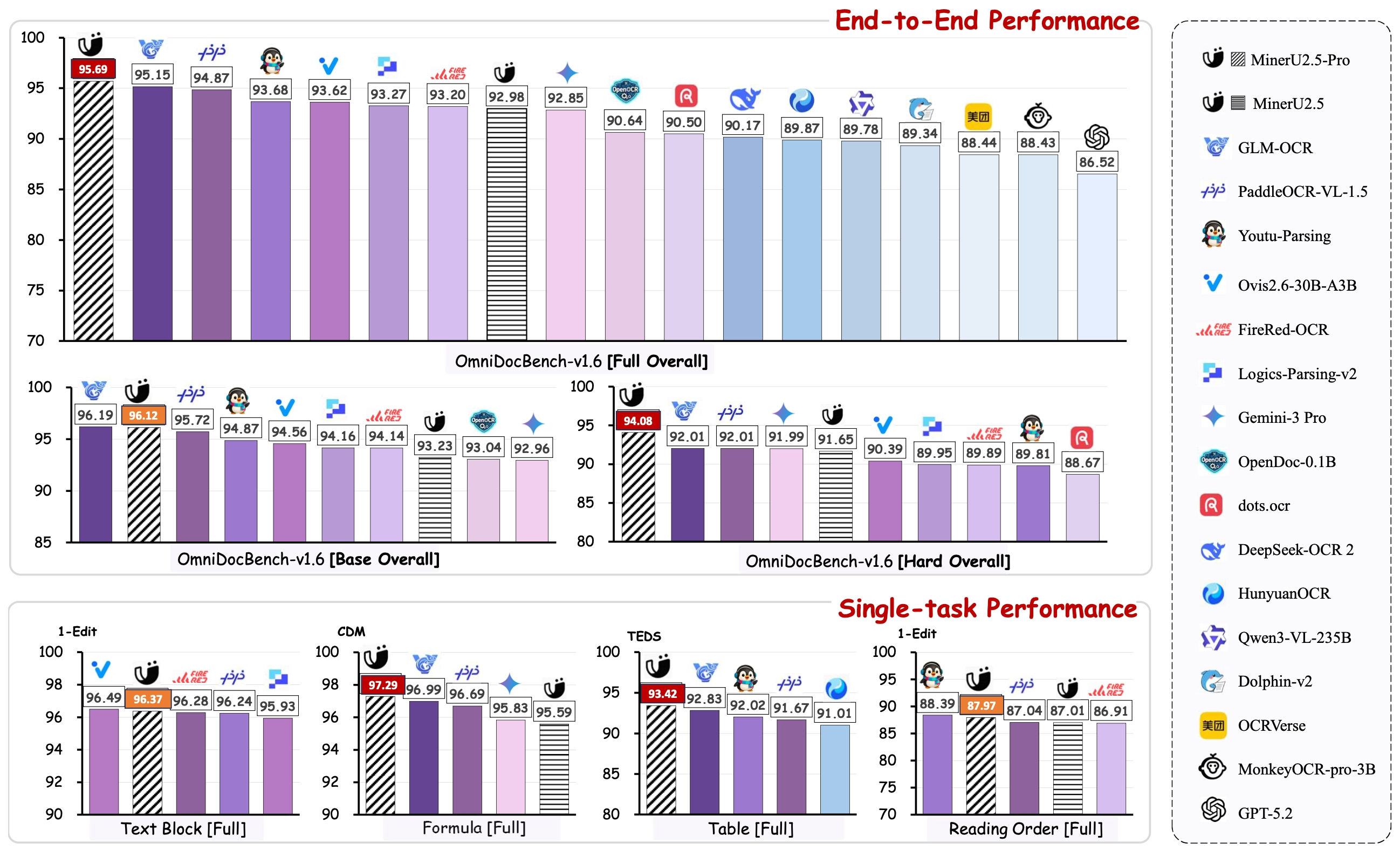
Section titled “Why MinerU + serverless”- Accuracy. The
MinerU2.5-Pro-2605-1.2BVLM leads the OmniDocBench leaderboard on text, formula, table, and reading-order metrics — see the HuggingFace model card and the technical report. - Economics. Per-second billing on RunPod with FlashBoot means an idle worker costs nothing. ~$0.0003 per page on a 24 GB RTX 4090 (default) at current rates (see RunPod pricing; rates change).
- Licensing. MinerU is Apache 2.0 with explicit commercial thresholds (free below 100M MAU and $20M monthly revenue, with attribution). Among open-source GPU-class PDF parsers, that’s the cleanest license for production SaaS use.
How it compares
Section titled “How it compares”| mineru-runpod | Marker | GROBID | Nougat | |
|---|---|---|---|---|
| Scale-to-zero | ✅ ready to use | ⚠️ possible, needs extra setup | ❌ always-on | ❌ |
| GPU | required | CPU or GPU | CPU | required |
| Equations | ✅ LaTeX | ✅ LaTeX | ❌ | ✅ LaTeX |
| Multi-lang | ✅ 109 (pipeline backend) | per upstream README | EN only | per upstream README |
| License | Apache 2.0 + thresholds | GPL-3.0 code + modified RAIL-M weights | Apache 2.0 | MIT code, CC-BY-NC 4.0 weights |
| Commercial SaaS | ✅ | ⚠️ depends on RAIL-M competitor clause | ✅ | ⚠️ subject to CC-BY-NC non-commercial clause |
Marker uses Surya as its in-process OCR/layout engine; Surya’s weights ship under a modified RAIL-M license. The license’s §2(c) competitor clause does not include the $2M revenue carveout that §2(a) and §2(b) carry, while Marker’s own README markets the model weights as free for “startups under $2M funding/revenue.” The two read differently — get counsel before depending on Marker for a service that could be characterized as competitive. Datalab’s Chandra model (what their hosted API runs) carries the same modified RAIL-M license.
See the project README for the fully source-cited version of this comparison.
What it accepts and what comes back
Section titled “What it accepts and what comes back”- Inputs: PDF, image (PNG/JPEG/GIF/BMP/TIFF/WebP), DOCX, PPTX, XLSX — auto-detected from bytes. Three transports: URL, base64, or a path on a mounted volume. See Input formats.
- Outputs: Markdown +
content_list+middle.json+ extracted images. Three transport modes: base64 tarball, inline fields, or presigned URL to an S3-compatible bucket. See Output modes. - Backends: five MinerU backends — the VLM (model card tagged English + Chinese; empirically handles Cyrillic correctly on the Pro model), the pipeline OCR (109 languages via PaddleOCR, documented-safe for any non-Latin script), the hybrid auto-router, and split-tier deploys. See Picking a backend.
Next steps
Section titled “Next steps”There are two paths from here, depending on whether you want to run the official image as-is or run your own customised build:
Easiest — deploy from the RunPod Hub. Sign up via this referral link, open the mineru-runpod Hub listing, and click Deploy. Grab the endpoint id and you’re parsing PDFs.
Customise — fork and auto-build. Fork the repo, then in the RunPod dashboard do The Hub → Serverless repos → Import Git Repository pointed at your fork. RunPod builds the image on every push to main. Use this path if you need to pin different MinerU / vLLM versions or modify handler.py.
Either way, total wall time is roughly 10 minutes assuming RunPod has spare capacity. See the project README’s Deploy section for the full step-by-step.